Research
My research statement is here. Few research problems where I am actively seeking student involvement are described below (in no particular order).
Distributed Program Verification and Synthesis
Distributed systems are workhorses of internet-era computing. While distributed computing has become ubiquitous, the complexity of programming however has remained high, resulting in deep and subtle bugs that are sometimes be exploited to the detriment of safety-critical systems. Verification preempts most such bugs by producing a machine-certified proof that the system satisfies its specification, however the cost of manual verification remains exceedingly high. Modelchecking (à la TLA+) is a low-cost mostly-automated alternative to verification, but modelchecking is effective only on specifications (or model implementations), leaving open the possibility of bugs in real implementations. In this context, it is pertinent to ask the following question:
Is there a non-trivial sub-class of distributed programs for which we can construct a mostly-automated verification procedure? How effective would the verification be in practice?
Alternatively, one might ask similar question in the context of synthesis:
Is there a non-trivial sub-class of distributed programs that can be synthesized from their (declarative) specifications? How competent are the synthesized programs in practice?
These research questions are relevant not only to the commercial distributed computing enterprise, but also to the future of internet-scale computing in general. As people gradually move away from trusting few large corporations with their data and computation, large-scale decentralized architectures (e.g., blockchains) and local-first software become the norm. In this context, it is worthwhile to pursue the dream of a programming framework that lets individuals own their data and help them deploy local-first decentralized software with the same ease as they deploy centralized cloud-hosted software today.
Probabilistic Verification of Networked Systems
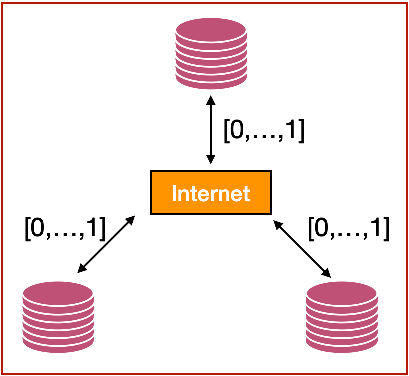
Conventional program verification answers a yes-or-no question: given a program and a machine, is it provably safe to execute the program on the machine? Safety is generally defined as machine never reaching an undesirable state or never getting stuck. Unfortunately, real systems are fraught with uncertainties such as network partitions, message losses, and disk crashes, and proving safety under such system model requires programmers to account for black swan events through expensive mitigations (e.g., strengthening the consistency model, adding locks etc). An interesting alternative in this context is to change the nature of verification itself:
Instead of performing deterministic reasoning, can a program verification be formulated based on a probabilistic reasoning about program safety? Instead of giving a yes-or-no answer, can the verification establish numeric bounds on how much a system deviates from its safety condition?
Such a probabilistic verification framework could be useful in the context of applications such as online banking and e-commerce, where a slight deviation from safety condition is admissable in the interest of performance and ease of use, provided that such a deviation is quantifiable.
Program Reconstruction from Traces
Program synthesis is the task of synthesizing programs from various kinds of specifications, such as declarations in a formal logic specifying the program semantics, input-output examples describing the program’s I/O behavior, or execution traces capturing main events in the program’s execution. While synthesis based on logical specifications and input-output examples has received much attention in the research literature, trace-based synthesis has not elicited similar enthusiasm due to its limited applicability; traces are hard to generate without the program, and if a program exists then there is likely no need for synthesis. This is however not true in case of Program Reconstruction, which remains a major application of trace-based synthesis. Under Program Reconstruction, one attempts to reconstruct a program, whose source code is inaccessible, by observing a collection of its execution traces. Program Reconstruction has been used for digital forensics in the context of database applications, but the formal guarantees of such reconstruction remain an open question. Nonetheless, I believe there is much scope for exploring Program Reconstruction in the context of Machine Learning applications, where, if successful, reconstruction could lead to significant reductions in the model generation time.